
Label Source: Meaning, Types, Benefits, and Comparison Guide
Label Source: In the digital era, information has turned into one of the most important assets of businesses, researchers, and technology companies. Nevertheless, raw data in itself is hardly ever helpful without a context. This is the point in which label sources are involved. A label source, which may be defined as a label source, gives the source or method of labelling, tagging, or annotating data. They are labels that assist systems in knowing what these data is about and can thus analyse and categorise easily to make decisions.
Label sources are useful either to train artificial intelligence models, arrange product catalogs within e-commerce platforms, or provide a general interpretation of customer survey, among others. Data in the form of images, text, audio and other types of information would be hard to process by machines without labeling.
As an example, when a dataset consists of thousands of images, it is possible to label them as dog, cat, car, or building, where machine learning algorithms can understand patterns to identify similar objects in the future. The accuracy of the system with the data directly depends on the quality of the label source.
This paper discusses label source, its significance, types, differences in various labelling techniques, tools applied in labeling and best practices. Knowing how label sources operate, businesses and developers can enhance their data and come up with more stable systems.
What is a Label Source?
A label source is the source or generation of labels or annotations of a dataset. These labels define the features, classes or definition of data items.
Simply stated, a label source provides the answer to the question:
The labels may be made by humans, automated systems, crowdsourced contributors or already existing datasets. The accuracy and credibility of these sources will depend on the reliability of the sources used to label the data.
As an illustration, in a dataset of images that is to be used in training an AI model:
| Image | Assigned Label | Label Source |
| Photo of a dog | Dog | Human annotator |
| Image of a traffic light | Traffic Signal | Machine learning algorithm |
| Image of a road | Road | Public dataset |
Without labelled sources, data would remain raw and unstructured, making it difficult for computers to interpret.
Types of Label Source
Here’s a clear explanation of the types of label sources, commonly used in manufacturing, packaging, and product identification:
| Type of Label Source | Description | Common Uses |
| Direct Thermal Labels | Labels that darken when exposed to heat; no ink or ribbon required. | Shipping labels, receipts, barcodes, inventory tags. |
| Thermal Transfer Labels | Requires a thermal ribbon; heat transfers ink onto the label surface. | Durable product labeling, outdoor labeling, chemical bottles. |
| Paper Labels | Traditional labels made from paper; can be coated or uncoated. | Retail products, packaging, short-term identification. |
| Synthetic / Plastic Labels | Made from materials like polypropylene, polyester, or vinyl. | Waterproof, tear-resistant labels for industrial, chemical, or outdoor use. |
| Writable Labels | Labels designed to be written on with pen, marker, or pencil. | Inventory, shipping, temporary labeling. |
| Pre-Printed Labels | Printed in bulk with company branding, logos, or standard info. | Product packaging, brand labeling. |
| Pressure-Sensitive Labels | Stick using adhesive; peel-and-stick type. | Food & beverage packaging, cosmetic products, shipping labels. |
| Shrink Sleeve Labels | Flexible labels that shrink to fit the container when heated. | Bottles and irregularly shaped containers. |
| Security / Tamper-Evident Labels | Labels that indicate tampering or unauthorized access. | Pharmaceuticals, electronics, sealed packages. |
| RFID / Smart Labels | Embedded with radio frequency identification or NFC chips. | Inventory tracking, anti-theft, supply chain management. |
| Heat-Resistant / Cryogenic Labels | Can withstand extreme temperatures without fading. | Laboratory samples, freezer storage, industrial environments. |
| Eco-Friendly / Recyclable Labels | Made from sustainable materials or recyclable paper/plastic. | Environmentally conscious product packaging. |
Why Label Sources Matter
Label sources are fundamental in many industries because they enable systems to understand and process data efficiently.
Improves Data Interpretation
Labels give meaning to raw information. Instead of just storing numbers, pixels, or words, labels help identify what the data represents.
For instance:
- An image becomes “cat” instead of random pixels.
- A customer review becomes “positive feedback” instead of plain text.
Essential for Machine Learning
Machine learning models rely on labelled data to learn patterns. The better the labels, the more accurate the predictions.
For example, an AI model trained to detect diseases in medical images must learn from accurately labelled images.
Helps Organise Large Data Sets
Modern businesses deal with huge volumes of data. Label sources help categorize and structure this information.
Examples include:
- Product categories in online stores
- Tags for blog articles
- Sentiment labels in customer feedback
Enables Automation
Labels allow automated systems to make decisions based on structured information.
Examples include:
- Spam detection in email
- Image recognition systems
- Voice assistants understand speech commands
Label sources can come from multiple methods depending on the dataset and the purpose of labelling.
Common Label Source Methods
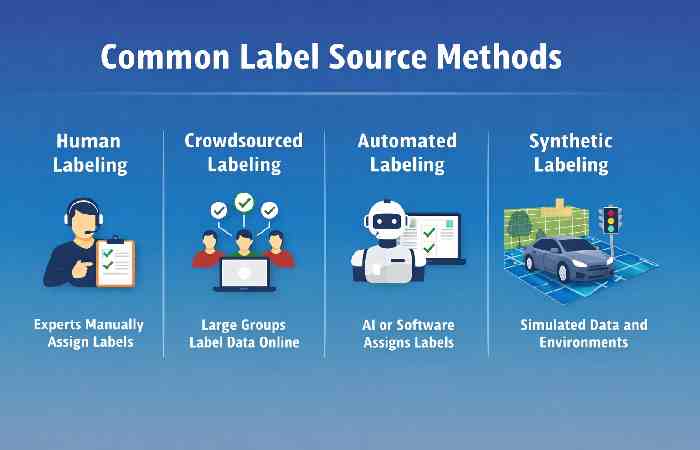
| Label Source Type | Description | Typical Use Case |
| Human Labeling | Experts manually assign labels | Medical imaging |
| Crowdsourced Labeling | Large groups label data online | Image classification |
| Automated Labeling | AI or software assigns labels | Spam filtering |
| Synthetic Labeling | Labels generated from simulations | Self-driving car training |
| Pre-Labeled Datasets | Labels already exist in datasets | Research and academic projects |
Each of these methods has its own advantages and challenges.
Human Label Sources
Human labelling is one of the most accurate forms of data annotation. In this approach, trained individuals analyze data and assign labels based on predefined guidelines.
This method is commonly used when precision and contextual understanding are required.
Examples of Human Labelling
- Doctors label medical scans
- Linguists annotating language datasets
- Experts are classifying legal documents
Benefits of Human Labelling
| Benefit | Explanation |
| High accuracy | Humans understand context better than machines |
| Flexible interpretation | Can handle complex or ambiguous data |
| Reliable for specialised tasks | Suitable for medical or scientific datasets |
Limitations
| Challenge | Description |
| Time consuming | Large datasets take longer to label |
| Expensive | Requires skilled professionals |
| Potential bias | Different labellers may interpret data differently |
Despite these limitations, human labelling remains essential for high-quality datasets.
Crowdsourced Label Sources
Crowdsourcing distributes labelling tasks among many people through online platforms. Instead of relying on a small team of experts, companies use large communities to label data quickly.
Crowdsourcing is often used when datasets contain millions of items that need labelling.
How Crowdsourced Labelling Works
- A company uploads data to a labelling platform.
- Workers receive instructions and labelling guidelines.
- Workers review the data and assign labels.
- Multiple workers verify the labels for accuracy.
Example of Crowdsourced Labelling
| Task | Number of Workers | Outcome |
| Label street images | 300 workers | Faster dataset creation |
| Tag product photos | 200 workers | Improved e-commerce categorisation |
| Analyse social media sentiment | 500 workers | Large sentiment dataset |
Crowdsourcing reduces costs and speeds up data preparation.
Automated Label Sources
Automated labelling uses algorithms or machine learning models to generate labels without human intervention.
This method is widely used when dealing with extremely large datasets.
Examples of Automated Labelling
- Email spam detection systems
- Automatic photo tagging in image apps
- Speech-to-text transcription tools
Benefits of Automated Labelling
| Benefit | Explanation |
| Fast processing | Can label millions of data points quickly |
| Scalable | Ideal for large datasets |
| Cost efficient | Reduces the need for manual labour |
Limitations
| Limitation | Explanation |
| Lower accuracy in complex tasks | Algorithms may misunderstand context |
| Initial training required | Needs labelled data to learn |
| Risk of bias | Model bias may affect labels |
Because of these limitations, automated labelling is often combined with human review.
Synthetic Label Sources
Synthetic labelling involves generating artificial data and labels using simulations or software environments.
This approach is helpful when collecting real-world data is difficult or dangerous.
Examples of Synthetic Labelling
| Industry | Example |
| Autonomous vehicles | Simulated traffic environments |
| Robotics | Virtual training environments |
| Gaming | AI character behaviour simulations |
Synthetic datasets allow developers to experiment without real-world limitations.
Label Source Comparison Table
Different label sources serve different purposes. Choosing the right one depends on the dataset size, accuracy requirements, and budget.
Comparison of Label Source Methods
| Feature | Human Labeling | Crowdsourcing | Automated Labeling | Synthetic Labeling |
| Accuracy | Very High | Medium to High | Medium | Medium |
| Speed | Slow | Fast | Very Fast | Fast |
| Cost | High | Moderate | Low | Moderate |
| Scalability | Limited | High | Very High | High |
| Best Use Case | Complex tasks | Large datasets | Real-time labeling | Simulations |
This comparison highlights why many companies adopt hybrid labelling approaches.
Applications of Label Sources
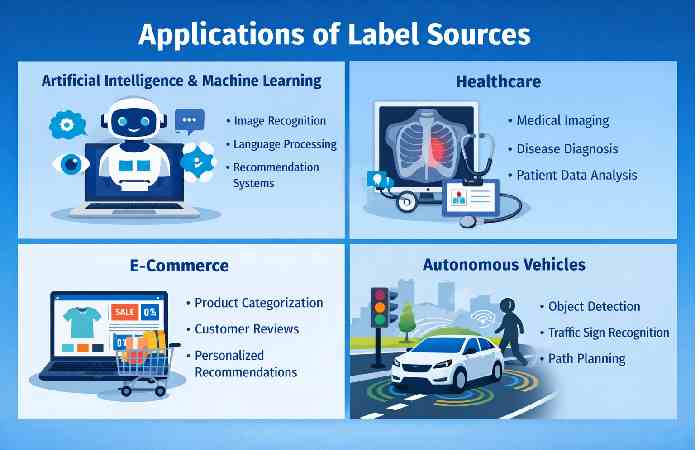
Label sources are used in multiple industries where data analysis plays an important role.
#Artificial Intelligence and Machine Learning
Machine learning models depend on labelled data to identify patterns and make predictions.
Examples include:
- Facial recognition systems
- Language translation tools
- Recommendation algorithms
#Healthcare
Medical research relies heavily on labelled datasets.
Example Medical Data Labelling
| Data Type | Example Label |
| X-ray image | Pneumonia |
| MRI scan | Brain tumor |
| ECG data | Heart rhythm disorder |
Accurate labelling improves diagnostic tools and healthcare research.
#E-Commerce
Online stores use labelling to categorise products and improve search results.
Example Product Labelling
| Product | Labels |
| Running Shoes | Sports, Footwear |
| Wireless Earbuds | Electronics, Audio |
| Organic Honey | Natural Food |
Labels help recommendation systems suggest relevant products to customers.
#Autonomous Vehicles
Self-driving vehicles depend on labeled visual data to understand their surroundings.
Important labels include:
- pedestrians
- traffic signs
- vehicles
- road lanes
- obstacles
These labels help autonomous systems navigate safely.
Tools Used for Data Labelling
Many software platforms help organisations manage label sources efficiently.
Popular Labelling Tools
| Tool | Main Function |
| Labelbox | Image and video annotation |
| CVAT | Open-source annotation platform |
| Supervisely | Computer vision labelling |
| Amazon SageMaker Ground Truth | Automated data labelling service |
| Scale AI | Enterprise data annotation solutions |
These tools simplify the process of creating, reviewing, and managing labels.
Challenges in Managing Label Sources
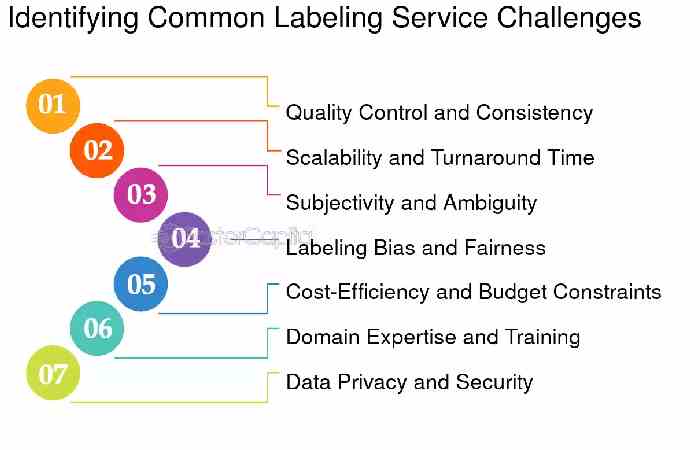
Although labelling is essential, organisations often face several challenges.
1. Data Quality Issues
Incorrect labels can significantly affect machine learning results.
Common problems include:
- inconsistent labelling rules
- missing annotations
- human errors
2. High Costs
Manual labelling requires skilled professionals, making it expensive for large datasets.
3. Labelling Bias
Human interpretations may vary, leading to inconsistent labels.
Example:
A review saying “This phone is okay” might be labelled neutral by one annotator and positive by another.
4. Scaling Problems
Large datasets containing millions of data points require automated or crowdsourced solutions.
Best Practices for Reliable Label Sources
Organisations can improve labelling quality by following certain best practices.
1. Create Clear Guidelines
Labelling instructions should include:
- label definitions
- examples
- edge cases
Clear guidelines help maintain consistency across annotators.
2. Use Multiple Reviewers
Having more than one reviewer improves accuracy.
| Review Type | Result |
| Single reviewer | Faster but less accurate |
| Double review | Improved reliability |
| Consensus labeling | Highest accuracy |
3. Combine Human and AI Labelling
A hybrid approach works best in many situations.
Example workflow:
- AI generates initial labels.
- Humans review and correct them.
- The system trains with improved data.
4. Monitor Label Quality
Regular audits help detect labelling errors early.
Methods include:
- random sampling
- performance testing
- dataset validation
Best Companies of Label Source
India
| Company | Head Office / City (India) | Specialty / Offerings | Notes |
|---|---|---|---|
| India Labels | Bangalore | Self-adhesive labels, barcode, RFID, custom printed labels | Established manufacturer & exporter since 1995 with custom solutions. |
| Sai Impression & Packaging Solutions | Chennai | Flexo & digital printed labels, container & specialty labels | Known for quality & large-volume capability. |
| JK Labels | Mumbai | Custom printed, thermal, hologram, barcode & security labels | State-of-the-art label printing and design facilities. |
| Dino Label Digital | Gurgaon | Custom labels & tapes with online order support | Flexible printing for various industries including food & beauty. |
| Duralabel Graphics Pvt. Ltd. | Mumbai | Barcode, blank & specialty labels | Broad label product range with modern infrastructure. |
| LabelTac India | Sonipat, Haryana | Adhesive label stocks, release liners & printing media | Specializes in top-quality label stock solutions. |
| Prakash Labels Pvt. Ltd. | Noida, UP | Custom label solutions & auto-ID products | 30+ years experience in labeling & tracking solutions. |
| TrueLabel (Truelabel.in) | Madhya Pradesh | Barcode, thermal, hologram & product labels | ISO-certified, precision & enterprise labeling solutions. |
| Pearl Paper Products | Ahmedabad, Gujarat | Custom & barcode labels | Cost-effective labels for multiple sectors. |
| Huhtamaki PPL Ltd. | Mumbai | Packaging & label solutions | Major flexible packaging & shrink sleeve/label producer. |
UK
| Company | Location / Base | Specialty / Offerings | Notes |
|---|---|---|---|
| Etiquette Labels Ltd | Wrexham, North Wales, UK | Printed & plain labels, self-adhesive labels, label printers | Trusted UK-made label manufacturer with 30+ years experience. |
| First Choice Labels | North East England, UK | Self-adhesive labels, plain & printed labels, pharmaceutical & food labels | ISO 9001 accredited, large-volume label production. |
| Langley Labels Ltd | Kings Langley, UK | Custom self-adhesive labels on rolls with various finishes | Expert advice and high-quality printing. |
| Mockridge Labels Ltd | UK | Digital & printed labels, domed & barcode labels | Premium label supplier with UL-accredited production capabilities. |
| Weber Packaging Solutions / Weber Labels | UK (part of global) | Self-adhesive & customised labels, tags, thermal labels | International label maker with ISO manufacturing. |
| UK Labels (Fortoak Group) | Oldbury, UK | OEM trade label manufacture, plain & printed solutions | Long-established trade label partner since 1986. |
| Limpet Labels UK Ltd | Wrexham, North Wales | Digital & flexographic labels in custom sizes | Award-winning label printing with fast turnaround. |
| Custom Labels Ltd | UK | Asset labels, heavy-duty & variable data printed labels | Specialises in industrial and long-lasting labels. |
Europe
| Company | Country / Region | Specialty / Offerings | Notes |
|---|---|---|---|
| HERMA GmbH | Germany | Self-adhesive labels, pressure-sensitive materials, labeling machines | One of Europe’s oldest and most respected label manufacturers, serving industrial & logistics markets. |
| Asteria Group | Europe (multiple sites) | Printed labels, flexible packaging, folding cartons | Pan-European label solutions with ~35 production sites; focus on sustainability & high volume. |
| CS Labels | United Kingdom | Digital printed labels & custom designs | European label producer using advanced digital printing tech for bespoke labels. |
| S&K LABEL | Central & Eastern Europe | Self-adhesive labels for diverse industries | Major regional label manufacturer, member of European label association FINAT. |
| MD Labels | Poland | Digital self-adhesive label solutions | Specialist in advanced inkjet UV label printing for custom & small-batch orders. |
| Label Ribbons (Labels-Ribbons.com) | Greece / UK | Barcode printer media, thermal labels, ribbons | Large European converter of blank labels & ribbons with wide distribution network. |
| Labelys Group | France & Europe | Adhesive industrial & specialty labels | Large label group covering multiple European markets with tailored solutions. |
| Stratus Packaging Group | France | Shrink sleeves, multipage & adhesive labels | Produces diverse label types for food, cosmetic & industrial sectors. |
| Alliance Etiquettes | France & Italy | Self-adhesive luxury & retail labels | Premium label printing & finishing with ISO certifications. |
| Reynders Label Printing | Belgium | Self-adhesive, shrink sleeves, smart labels | Established Belgian label manufacturer with a focus on sustainability and quality. |
Future of Label Sources
As artificial intelligence evolves, labelling methods will also improve.
Several trends are shaping the future.
AI-Assisted Labelling
AI will increasingly assist human annotators by suggesting labels automatically.
Self-Supervised Learning
Some advanced machine learning models can learn patterns without extensive labelled data.
Real-Time Data Labelling
Systems will label incoming data automatically in real time.
Collaborative Labelling Platforms
Cloud-based platforms will allow global teams to collaborate on labelling tasks.
Conclusion
Label sources play a critical role in transforming raw data into meaningful information. Assigning labels to datasets allows machines and humans to interpret data more effectively.
From human annotators and crowdsourced workers to automated systems and synthetic simulations, each label source method serves a unique purpose. Choosing the right labelling approach depends on factors such as dataset size, accuracy requirements, and available resources.
As data continues to grow rapidly across industries, the importance of reliable label sources will only increase. Organisations that invest in high-quality labelling processes will be better equipped to build accurate AI systems, improve data analysis, and unlock valuable insights from their datasets.
Understanding label sources is therefore not just a technical concept—it is a fundamental part of modern data-driven innovation.